Pasitaikė man toks dokumentas – „Valstybinės lietuvių kalbos komisijos protokolinis nutarimas dėl svetimžodžių atitikmenų sąrašo“, pasirašytas VLKK vadovės Irenos Smetonienės 2010 spalio 28 dieną.
Nesigilinsiu šį kartą į tai, ką ten prigalvoję yra kaitalioti (kaip visada, priežasčių pasijuokimams galima atrasti), tačiau pabandžiau tiesiog formaliai skaitiškai įvertinti tos komisijos darbo kokybę – kiek jie makliavoja, o kiek nuoširdžiai stengiasi. Kriterijus – labai paprastas: siūlomų keisti svetimžodžių pasiskirstymo atitikimas prognozuojamam statistiniam svetimžodžių paplitimui.
Prielaidos paprastos: pagrindinis svetimžodžių šaltinis šiuo metu yra anglų kalba. Taigi, galime tikėtis, kad lietuvių kalbos gaunamų svetimžodžių pasiskirstymas turėtų ganėtinai stipriai koreliuoti su pačios anglų kalbos žodžių pasiskirstymu. Pavyzdžiui, paprasčiausiu atveju – pagal pirmąją žodžio raidę.
Tuo atveju, jei VLKK dirbtų kokybiškai, sistemingai ir organizuotai ieškodama plintančių svetimžodžių bei pakaitalų jiems, dažniniai nuokrypiai nuo anglų kalbos pasiskirstymo turėtų būti ganėtinai saikingi, didele dalimi grafikai turėtų sutapti. Priešingu, prasto darbo atveju, turėtume gauti visiškai neatitinkančius pasiskirstymus.
Taigi, sumetam lentelę iš to dokumento, paskaičiuojam, sumetam greta angliškus pasiskirstymus ir gauname štai ką:
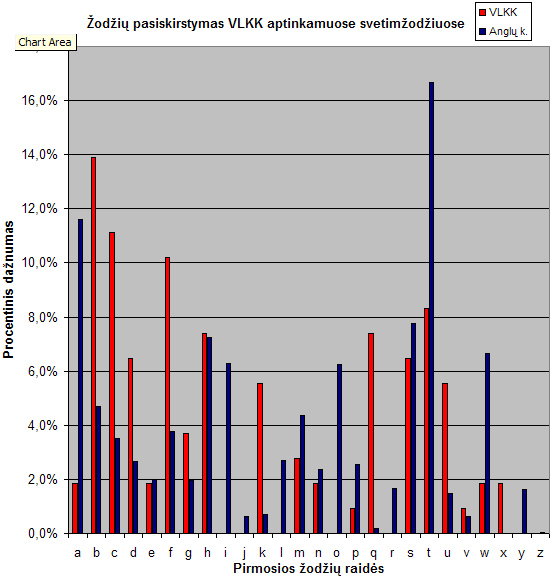
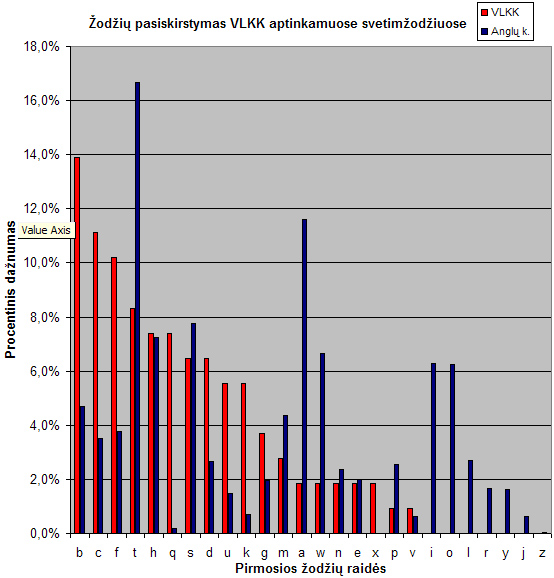
Grafikas vaizduoja lietuvių kalboje keičiamų svetimžodžių pasiskirstymą pagal VLKK (raudona) ir anglų kalbos žodžių pasiskirstymą (mėlyna)
Kaip matome, bendros koreliacijos nematome. Visiškai. Dar daugiau, įspūdis toksai, kad pradedant abėcėlės pirmomis raidėmis, VLKK dar bando dirbti aktyviai, tačiau įpusėjus abėcėlę, nuleidžia rankas ir daugiau jau nesistengia. Negana to, labai keistai atrodo kelių raidžių trūkumai – toks vaizdas, kad ieškant svetimžodžių, dirbta buvo visgi pagal konkrečias raides (t.y., ar tai kažkokiems darbuotojams paskirta rankioti svetimžodžius, ar šiaip, bet paraidžiui), tačiau dėl kažkokių neaiškių priežasčių kelios svarbios raidės tiesiog prapuolė. Fenomenaliai atrodo „a“ raidė – nors ir pirma, sąrašo pradžioje, tačiau visiškai menkai teparankiota.
Toliau esantys skirtumai tarp angliškų ir lietuviškų „b“, „c“, „d“ (praleidžiam iškrentančią „e“) ir paskui dar ir „f“ bei daugmaž „g“ – savo santykiais koreliuoja tarpusavy, t.y., atrodo, kad su šiomis raidėmis buvo dirbta kokybiškai, nuosekliai, jų santykiai atitinka ir mūsų darytą prielaidą apie atitikimą tarp svetimžodžių ir angliškų žodžių pasiskirstymo, patvirtindami, kad šito mūsų tyrimo konceptas teisingas.
Su „h“ raide jau prasideda kažkokie bardakai – bene vienintelė procentiškai atitinkanti raidė tampa išimtimi iš bendro grafiko. Su „i“ raide – išvis nei vieno svetimžodžio nerasta. Su „o“ – irgi. O juk šiomis raidėmis prasidedantys žodžiai užima 5-ą ir 6-ą vietą pagal populiarumą anglų kalboje. Dar kartą prisiminkim „a“ raidės fenomeną. Su juo palyginus, „w“ bei „l“ jau atrodo nekaltai.
Galų gale, dar toliau – išvis nelieka jokių abejonių: „t“ raide prasidedančių svetimžodžių VLKK atranda mažiau, nei atrado prasidedančių „b“, „c“ ar „f“ raidėmis. O juk „t“ raide prasidedantys anglų kalbos žodžiai – populiariausi. Kiek čia mums gaunasi? Maždaug keturių kartų skirtumas. Keturių kartų neatitikimas yra labai didelis, sakyčiau, užribinis, abejoti neleidžiantis. Kad tai nėra kažkokia fluktuacija, abejot neleidžia „m“, „s“ ir „w“ santykiai, kurie irgi panašūs.
Taigi, VLKK darbas, sprendžiant pagal statistinės atitikties realybei vertinimą, yra prastas, o pagal gautus duomenis (t.y., raidžių pasiskirstymų pobūdį) galime spėti, kad ten yra labai nemenkų organizacinių bėdų, susijusių su konkrečių užduočių vykdymu. VLKK dirba nesistemingai, prastai planuoja savo veiklą ir prastai kontroliuoja savo pačios darbą.
Ar ką nors bent truputį nustebinau?
Upd.: dar rūšiuotas grafikas pridėtas, kad kitu būdu pažiūrėt, aiškiau matosi pasiskirstymų neatitikimas.
-
- Grafikas vaizduoja svetimžodžių pasiskirstymą pagal VLKK (raudona) ir anglų kalbos žodžių pasiskirstymą (mėlyna)
-
- Tas pats grafikas, surūšiuotas pagal pasiskirstymų dažnumą anglų kalboje. Matosi, kad VLKK pikai visiškai neatitinka.
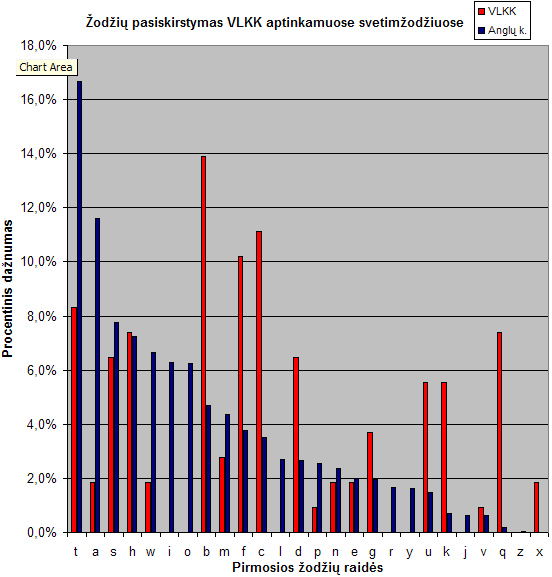
-
- Tas pats grafikas, surūšiuotas pagal pasiskirstymų dažnumą lietuvių kalboje. Matosi, kad anglų kalbos pikai visiškai neatitinka.
Rokiškis Rabinovičius rašo jūsų džiaugsmui
Aš esu jūsų numylėtas ir garbinamas žiurkėnas. Mano pagrindinis blogas - Rokiškis Rabinovičius. Galite mane susirasti ir ant kokio Google Plus, kur aš irgi esu Rokiškis Rabinovičius+.
- Web |
- Google+ |
- More Posts (1489)

hackas
nustebinai.
🙂
žodžiai ne kariuomenėje -- paal abėcėlę nevaikšto.
Vaikšto panašiai, kaip ir kitose kalbose. Atitinkamai.
Detaliau kalbant: jei iš karinio dalinio, turinčio 5000 kareivių, 100 išeis į miestą, prisigers, pridebošyrins ir bus nubausti, jų vardų pirmų raidžių pasiskirstymas turės būti panašus į tą pasiskirstymą, kuris yra pas visus 5000.
Tuo atveju, jei neatitikimai yra labai dideli, reiškia, kad yra faktoriai, įtakojantys pagal raides. Pvz., kareivių sąrašas pagal raides, kur baudžiamus debošyrus išrinkinėja dalinio vadas, kuriam, pervertus pirmus sąrašo puslapius, nusibosta, jis ima versti ir išrinkinėti baudžiamuosius, praleisdamas lapus ir t.t..
Štai tą iš grafikėlio ir matome.
Sakai: „Kriterijus – labai paprastas: siūlomų keisti svetimžodžių pasiskirstymo atitikimas prognozuojamam statistiniam svetimžodžių paplitimui.“
Nesuprantu. Svetimžodžių pasiskirstymo kur? Statistiniam paplitimui svetimžodžių kur? Internetuose? Žodyne? Jaučiu žodyne…
Beje, o nenorėtum grafiko papaišyti ir rusų kalbai (fonetiškai pagal raides)?
Beje, o gal VLKK naudoja kitokį metodą savo darbo kokybei aprašyti? 🙂 Gal jie dirba intensyviai rinkdami žodžius iš žiniasklaidos ir medijos? Ir nesiremia jokia žodynų statistika?
Rusų kalbai daryti grafiko nėra prasmės -- tame dokumente nėra nei vienos svetimybės iš rusų kalbos. Tas ir natūralu -- iš jos svetimžodžių dabar beveik neateina.
O kokia statistika VLKK remiasi ar nesiremia, tai įtakos nedaro. Žodynų statistika tiesiog rodo natūralius pasiskirstymus, kurie daugiau mažiau turi atitikti, bent jau tiek, kad koreliaciją turi likti. Paskiruose to grafiko fragmentuose koreliacija matosi, bet tik fragmentuose.
Naivu manyti, kad svetimžodžiai yra tik iš anglų kalbos.
Kita vertus, net nelabai aišku, kokiu principu grafiką sudarei.
Pastebiu pastaruoju metu, kad visi tik vieni kitus linkę šmeižti ir menkinti dėl vienų ar kitų dalykų, kurie jie patys nenutuokia.
Patariu pamatyti VLKK darbą iš vidaus, ne tik iš to, kas tau čia vieną kartą į rankas papuolė, tada ir galėsi vertinti darbo kokybę.
Bla bla bla.
Brangi Inga, truputį pagalvojau ir suprantu tamstos bėdą, tad paaiškinsiu tamstai paaiškinu aiškiau: tamstos pezėjimai, paremti prielaidomis apie tai, ką aš naiviai manau ar nemanau, yra irelevantiški.
Minimame dokumente yra 108 žodžiai, iš jų ~70 angliški. Kitų kalbų įtaka -- foninė, pvz., antra pagal dokumentes esančių žodžių paplitimą yra italų, kuri duoda tik 14 žodžių (penktadalį nuo angliškų kiekio), trečia yra ispanų -- duoda 7 žodžius. Todėl šitos kalbos gali duoti tik saikingą nuokrypį, bet ne kardinalią įtaką. Panašiai tiktai nuokrypį, bet ne kardinalią įtaką gali duoti kokios nors esamos lietuvių preferencijos ar įvairūs atsitiktinumai.
Dėl tamstos pasažo apie šmeižimą ir tai, ko kas nenutuokia: tamsta nenutuokiat, bet šnekat ir piktinatės. Skaičiams visiškai nesvarbu, kas jais skaičiuojama. O žodžio „šmeižimas“ prasmę tamstai reiktų pasiaiškinti, gal tada sužinotumėte, kad vertinimas nėra šmeižimas.
Dėl VLKK darbo pamatymo iš vidaus -- aš jį pamačiau pagal vieną iš pagrindinių to darbo rezultatų. Pagal tą dokumentą, kuris į rankas papuolė. Šio tipo dokumentų (svetimžodžių ir siūlomų pakaitalų sąrašų) kūrimas yra vienas iš VLKK pagrindinių darbų, tiesa? Taigi, matome, kad sąrašai kardinaliai neatitinka natūraliai tikėtinų pasiskirstymų, t.y., rodo VLKK darbo kokybės bėdas.
įdomus grafikas palyginimui, gerai padirbėta. tik aš bijau, kad duomenys pasirinkti statistinei analizei gali būti šiek tiek neteisingi. Turiu omenyje, kad anglų kalbos žodynai yra be galo dideli (didžiausi pasaulyje, in fact) ir žodžių gausa nelygu žodžių populiarumui.
Nes kad ir kaip būtų, svetimybėmis dažniau tampa užsienio kalboje populiarūs žodžiai, o jų pasiskirstymas nebūtinai yra toks pat kaip visų žodžių kalboje.
Nesakau, kad rezultatai būtų kitokie ar kad parodtytų geresni/blogesni VLKK darbą, tiesiog tai vienas punktas prie ko būtų galima akademiškai prikibti.
O šiaip -- įdomu. Vel dan.
Pasiskirstymai gali nukrypti, svyruoti, etc., visas grafikas ir nepretenduoja į rimtumą. Esmė tiesiog ta, kad koreliacija turi likti pakanakamai ryšiki, atspindinti svetimžodžių kelią į lietuvių kalbą. Būtent toksai atitinkantis fragmenas matosi periode b-c-d.
Tačiau pagrindinėje grafiko dalyje labiausiai matomi kiti faktoriai, pagal savo pobūdį -- aiškiai susiję su darbo organizavimu.
biški nesupratai, ką norėjau pasakyti. Anglų kalba pati yra stipriai įtakota įvairių užsienio kalbų. (toliau nepateikiu jokių visiškai tikslių duomenų, tiesiog pavyzdžiais parodau situaciją, kurioje tavo grafikas GALI neteisingai atspindėti situaciją). Tarkime iš 500,000 žodžių anglų kalboje, 60% procentų yra atėję iš prancūzų kalbos. tarkime toje kalboje yra paplitę žodžiai iš raidės T, kas pakeičia ir pačios anglų kalbos statistiką pagal raides. taip pat tarkime, kad bendrinėje šnekamojoje anglų kalboje tokie žodžiai kilę iš prancūzų kalbos nebėra labai dažnai vartojami -- jie labiau sutinkami literatūrinėje kalboje ar kokių nors sričių techninėje/akademinėje literatūroje. Gauname situaciją, kurioje nors žodynas turi daug žodžių iš raidės T (nes jie daugumoje atėję iš prancūzų kalbos ar dar kokios kalbos X), tačiau dauguma jų yra ne populiarūs ir svetimybėmis kitose kalbose nevirsta. Dabar dar įsivaizduok, kad tarkime dauguma žodžių prasidedančių b-c-d yra populiarūs būtent dabartinėje šnekamojoje anglų kalboje.
Summa summarum, aš manau, kad tavo prielaida, jog populiariausių žodžių grafikas pagal raides turėtų kaip nors prasmingai koreliuoti su visų kalbos žodžių grafiku pagal raides, yra nepagrįsta. (nesakau neteisinga, sakau -- nepagrįsta).
Daugumoje Vakarų Europos kalbų garsų pasiskirstymai yra gan panašūs. Tai susiję su tuo, kad visos šios kalbos yra bendrakilmės. Aš suprantu tamstos prielaidas apie galimus giluminius faktorius, tačiau būtent tamstos prielaidos nėra pakankamai pagrįstos. Jas neigia ir pastebimos sekos, kur atitikimai tarpusavio santykiuose tarp svetimybių ir raidžių yra, kokių ir galima tikėtis (žr. b, c, d), ir pačios VLKK nurodoma angliška žodžių kilmė.
Taigi, summa summarum, kol kas tamsta nepateikėte rimtesnių argumentų, leidžiančių abejoti mano prielaidomis. Rimtesnius žemiau pateikė Laiqualasse, ten išties yra dėmesio verti.
Soriukas, bet kadangi tu kažką teigi tai įrodymo našta tenka tau. Aš tiesiog savo postu bandžiau nurodyti vietas, kur tau ta našta slįsta iš rankų. :] nes kol kas teturi b-c-d kurios pagal tave gražiai koreliuoja ir iš to nusprendei padaryti išvadas.
Viską nustato modelis -- jis yra pačiame dokumente, duodančiame 70 procentų angliškų žodžių. Tai yra pakankamas įrodymas pats savaime, toks pakankamas, kad mane stebina, kad tau tai nedašyla. Sekos, kurios atitinka -- yra tik papildomas patvirtinimas tam pačiam modeliui ir rodo atkuriamumą pagal rezultatą.
Jei tu nori neigti, kad anglų kalba yra tapusi dominuojančiu donoru -- tai bus problematiška. Šnekos apie „įrodymo našta tenka tau“ nereiškia nieko -- viskas kaip ant delno.
Kita vertus, jei tu esi pakankamai bukas, kad akivaizdūs dalykai nedašiltų -- nemanau, kad verta diskutuoti. Taip kad apsispręsk.
Kalbant visai bukai: tiesinis modelis yra paprasčiausias. Teigdamas, kad jis netiesinis, tu įvedi papildomą grandį, kurią įrodyti reikia būtent tau. Ar supranti tai?
labai piktai šneki, rokiški. kam gi taip? Čiliaks truputėlį, diskusija čia, ne ginčas.
Grįžtant prie temos. įrodymo našta būtų mano, jeigu tu savo VLKK kritiką sėkmingai būtum pagrindęs. Ir pagrindimu aš visiškai nelaikau subambėjimo, kad kažkas yra „paprasčiausia“ nežiūrint į duomenis. Diskutuojant apie kalbą yra daugybė kintamųjų apie kuriuos reikia pagalvoti prieš pradedant sudėtingesnes teorijas Okamu pjaustyt.
Aš tau pateikiau klausimą iš kur tu žinai, kad dažniausios pirmos raidės žodynę yra lygu populiariausioms pirmoms raidėms šnekamojoje kalboje. Jei nežinai ar taip iš tikrųjų yra, o tik spėji iš lubų -- nepyk šitaip, o tiesiog pasidomėk. Tarkim šimtas populiariausių angliškų žodžių pagal savo pirmą raidę labai prastai koreliuoja su tavo pirmos raidės grafiku. Susirasi ar tau parodyt?
Peace.
Dvi klaidos viename pavyzdyje: pirma -- įvedama fantastinė prielaida, esą žodžio migracijos į kitą kalbą tikimybė proporcinga to žodžio vartojimo dažnumui kalboje donorėje, o ne atsitiktinei artima, antra -- pavyzdys parimtas išimtimis, t.y., didžiausiais nuokrypiais nuo normos, kurie darant vertinimus, būna atvirkščiai -- išmetami. Sprendžiant iš šitos tavo duomenų denormalizacijos (pzpzpz), spėju, kad su statistika tu nelabai susidūręs, tiesa?
O apie tuos „daugybė kintamųjų, apie kuriuos reikia pagalvoti“ ir pan. -- kadangi paskirstymai šiame vertinime yra pagal raides, tai surask tų kintamųjų, kurie veiktų, kaip filtras toms raidėms žodžių migracijos metu. Ir išsispręs klausimas.
Kad būtų paprasčiau ieškoti: nepriklausomi kintamieji, grubiai imant, statistiškai nesisumuoja, likdami fonu, t.y., antraielių faktorių kiekis neturi didelės reikšmės. Ieškok faktoriaus, kuris būtų kardinalus, t.y., pavieniui lenkiantis to paties angliško pasiskirstymo įtaką.
Ir dar: tavo nesupratimas nėra argumentas. Jei tau nesuprantama kažkas, kas akivaizdu -- tai yra tavo problema, kurią reikia išspręsti tau. Nekompetencija nėra argumentas. Ir tai neturi nieko bendra su piktumais.
Rokiški, panašu, kad tu visiškai neįsivaizduoji, ką VLKK dirba ir kaip yra dirbama su svetimžodžiais ir jų pakaitalais. Kitaip tariant, grafikas paremtas visiškai neteisingomis prielaidomis. Ir, galiu tik pritarti Aurelijui -- „žodžiai ne kariuomenėje – pagal abėcėlę nevaikšto“.
Grafikas paremtas prielaidomis, kurių tu negali paneigti, Maumai. Visa kita -- tavo tuščiažodžiavimas, kurio tu irgi negali pagrįsti.
Logika yra labai paprasta: inputo pasiskirstymas pagal faktorių, kuris neįtakojamas, turi atitikti outputo pasiskirstymą pagal tą patį faktorių. Šiuo atveju pasiskirstymas yra pagal raides, inputas -- anglų kalba, outputas -- minėtas dokumentas.
Įrodyti, yra kažkoksai natūralus inputo filtras (pvz., svetimžodžių vartotojų preferencijos), kardinaliai iškreipiantis žodžių pasiskirstymus -- vargu, ar įmanoma.
Taigi, pagal tai lieka daryti išvadą, kad filtras yra pačioje VLKK. Ir, ką rodo pasiskirstymai -- tikrai yra: VLKK darbuotojos dirba, pildydamos sąrašus pagal konkrečias raides, pvz., žodžiai iš „a“, žodžiai iš „b“ ir t.t.. Vat tuos iškreiptumus ir matome.
Kitą kartą, prieš prieštaraudamas, galvok.
Gerai, tuomet, garbusai, aprašyk man, kaip gi kalbininkai dirba su tais svetimžodžiais. Nuo svetimžodžio suradimo iki jo eliminavimo arba atitikmens pasiūlymo.
Neteisingas klausimas nuo pat pradžių. Kadangi pats esi teisininkas, duosiu tau pavyzdį:
Tarkim, turime 60 Lietuvos savivaldybių. Kiekviena turi gyventojų X ir nusikaltimų per metus Y. T.y., kiekvienai galim išvesti santykį tarp nusikaltimų ir gyventojų skaičiaus.
Jei santykis skirtingose savivaldybėse svyruoja saikingai, galime tarti, kad yra bendras, sistemingas kovos su nusikalstamumu organizavimas, t.y., kur nusikalstamumas iškyla, ten kovojama smarkiau ir t.t.. Bet jei vietoje ganėtinai tolygaus (pvz., keliasdešimt procentų svyravimo) grafiko gauname krūvas duobių ir pikų, kur nuokrypiai į vieną ar kitą pusę sudaro pvz., 4 kartus (t.y., šimtus procentų), tai galime kalbėti apie blogai organizuojamą teisėsaugos darbą.
Akivaizdu, kad tokiam įvertinimui visiškai nebūtina žinoti policininkų ar tardytojų darbo tvarkos ir nusikaltimų tyrimo metodikos.
Tuo tarpu apie svetimžodžių suradimą irba atitikmens siūlymą -- tą ir matome: dirba, rinkdami svetimžodžius pagal raides, nes pagal jas matome pikus. Pagal vienas raides kaip reikiant pasistengia (b, c, d, f, k, q, u), tuo tarpu kitas dirbdami, sumala šūdą (a, i, o, t, w). Pasiskirstymų pobūdis leidžia įtarti, kad yra keletas darbuotojų su labai skirtinga darbo kokybe. Atitinkamai, toks pasiskirstymų perdavimas į galutinius rezultatus leidžia įtarti, kad jų darbo kokybė nėra kontroliuojama, klaidos nėra taisomos.
Ar dabar truputį aiškiau? 🙂
Kuo toliau, tuo labiau nesuprantu tavo pradinės idėjos. Apskritai, prie ko čia pirmosios raidės? Niekas ten pagal pirmas raides nedirba, žodžių negaudo ir pan. Ir vienu momentu gali ateiti visa serija svetimžodžių, pvz., prasidedančių „c“ ir nei vieno -- „x“. Tai kokios dar gali būti koreliacijos?
Maumai, jei tarsim, kad yra pagal tavo prielaidą, tokiu atveju VLKK išvis neturi jokio sistemiškumo ir tai yra dar blogiau, nei aš teigiu. T.y., kad kažkas už juos kažką daro iškreiptais būdais, dėl kurių atsiranda pikai ir gapai, o pats VLKK išvis bbž kuo užsiima. Ar tu tai nori pasakyti?
Ta prasme, tu nori pasakyti, kad aš esu VLKK gynėjas? Odnako nixuja sibe :-/
Rokiški, tai gi būtent aš dėl to ir klausiau, ar tu žinai, kaip „medžiojami“ svetimžodžiai ir kokia jų medžioklėje VLKK rolė?
Maumai, visiškai dzin. Sprendimus daro VLKK. Jei yra teisės sprendimams, reiškia, turi būti ir atitinkamos pareigos. Jei yra pareigos -- reiškia, ir veikla. Tą veiklą ir analizuoju, pagal pačios VLKK teikiamus duomenis.
Jei tai yra ne VLKK veiklą atspindintys duomenys, o tik kažkokia su VLKK realiai nesusijusi beliberda, prie kurios Smetonienė tik savo parašą prilipdė, o mopedas ne jos, o tik abjava jos -- tai tiesiai ir įvardink.
Taip ir išsispręs reikalas -- tarsim, kad čia kažkas kiti tuos nuokrypius daro, o tuo tarpu VLKK tiktai pinigus eikvoja.
Nu?
E… Rokiški, manau, kad fail… Idomiai išlankstei, darbas atliktas gražiai, bet manau, jog duomenys yra neteisingi. Esu 99,9% įsitikinęs, kad anglų kalbos žodžių pasiskirstymas pagal raides neatitinka svetimžodžių pasiskirstymo lietuvių šnekamojoje kalboje. Be to, jeigu imsime vartojimo pasiskirstymą tai, bus visiškai kitas vaizdas. Apibendrintai, tavo fail priežastys:
a) ne visi anglų k. žodžiai virsta svetimžodžiais LT kalboje
b) ne visi vienodai paplitę
Neteisinu VLKK ir neturiu žalio supratimo kaip jie dirba ir apskritai, kodėl kartais priima tam tikrus sprendimus, tačiau faktas, kad tavo analizė abejotina 🙂
Bendro svetimžodžių pasiskirstymo žinoma, kad neatitinka. Tačiau šitas dokumentas yra papildomasis, 2010 metų -- jame yra 108 nauji žodžiai, 71 iš anglų kalbos. Kitų kalbų įtaka gaunasi foninė, ji, kaip ir kiti nuokrypiai, gali sudaryti keliasdešimt procentų, nuokrypius, tačiau ne keturių kartų, kokius matome grafike.
Trumpai tariant, mano feilo nėra -- yra tiktai tamstos nesupratimas. Tamstos nesupratimas yra pagrindas abejoti tamstos supratimu, bet ne mano.
Prirariu Maumaz ir Aurelijus. Trumpai abu parašė, bet aiškiai. Daugiau nelabai ką bepridėsi.
Tavo pritarimas tiesiog rodo, kad tu reaguoji, remdamasis ne duomenų vertinimu, o reflektyviai, maždaug kaip galvijas 🙂 Tai nėra reakcija, kuri būtų kažko verta 🙂
Na, anuo komentaru aš ir nepretendavau į kokią tai išliekamą vertę 🙂 Šiaip, išreiškiau pritarimą. Kiek daugiau rašyti šiuo metu tingisi kairiąka ranka (be to kairė -- sinister- lemia piktą). Bet va tos išvados, kurias kurias tu padarei iš tos mano, kad ir nelabai vertingos, pastabos apie tave daugiau pasako, nei apie mane.
Taip, apie mane mano pastaba pasako išties daug: visiškai nevertinu neargumentuotų teigimų ar neigimų, ypač kai tie teigimai ar neigimai paremti kitais neargumentuotais teigimais ar neigimais.
Jei rimčiau žiūrėsim, aš matau čia rimtesnę bėdą: tai, kas man visiškai akivaizdu (gal dėl to, kad analizes pagal skaičius esu daręs daugybę kartų), kitiems kažkodėl nesuprantama.
Ir, pvz., netgi toks, atrodytų, akivaizdus dalykas, kad nekoreliavimas reiškia nekoreliavimą, kas, esant aiškiai priežastinei sekai, reiškia vykdomą tos sekos iškreipimą -- kažkam nesuprantama tiek, kad kyla noras tai neigti.
Vat dabar ir galvoju, ar čia užsiimt kokia nors švietėjiška veikla, ar šiaip siuntinėt visus, kaip esu įpratęs.
Pats tu galvijas. Ir dar bebras 😀
O tai ką man dabar į tai atsakyt? Argi mano teiginys, kad „ne, ne galvijas ir ne bebras“ galėtų būti argumentu? Manau, kad ne :-/
Contra factum non valet argumentum.
Verbum non penis, in manus non recipi.
Nežinau, kiek teisingos Rokiškio prielaidos, bet dėl vieno dalyko jis teisus -- VLKK nedirba. O jei tiksliau, tai dirba savo deklaruojamą darbą tik tada, kada lieka laiko nuo visuomenės nuomonės formavimo dienraščių komentarų skiltyse. Gan smirdinti kontorėlė
Iš esmės, tamstos pasakymas „dirba savo deklaruojamą darbą tik tada, kada lieka laiko“ atitinka grafiko rodomus požymius -- kad vietomis bandyta dirbti, o vietomis tiesiog nieko nepadaryta.
Labai fainas grafikas, primena pasipiktinųsį ežį, ale absoliut-nesupratau, ką norima juo parodyti (gal reikėjo palyginti normaliai naudojamų Lietuvoje tarptautinių žodžių skaičių, normaliai prigijusių sulietuvintų žodžių skaičių ir per jėgą sulietuvintų ir neprigijusių žodžių skaičių, jei tik tokią statisitką būtų įmanoma surinkti).
Bet VLKK kaip šūdkrapščių kontorėlės vertinimui visiškai pritariu.
Grafikas rodo paprastą dalyką, tūpą tiesiog: kaip ėmė ir lietuvino įvairius svetimžodžius. Iš pasiskirstymo atsekama, kad ėmė paraidžiui (pvz., ėmė ieškoti, o paskui lietuvinti žodžius iš „a“, paskui -- iš „b“ ir t.t.), bet su kai kuriomis raidėmis dirbo nuoširdžiai, o kai kurias praleido išvis paxuistiškai.
Prigijusių sulietuvintų žodžių skaičiai ir neprigijusių sulietuvintų žodžių skaičiai būtų itin įdomūs, deja, neįsivaizduoju, pro kur tokius duomenis gauti. Net ir VLKK man atrodo neturi tokių duomenų, ypač už periodus, mažesnius, nei kokie 10 metų. Kita vertus, jie rodytų šiek tiek kitus dalykus.
aha, dėl grafiko dabar aišku
Sakai, VLKK darbą vertinai pagal duomenis dokumento, kuriame yra 108 žodžiai, iš jų 71 atėjęs iš anglų kalbos? Tai yra vidutiniškai 4,15 žodžio vienai (anglų abėcėlės) raidei, o iš anglų kalbos atėjusių žodžių išvis 2,73. Labai labai grubiai imant, duomenų variacija (vieno standartinio nuokrypio) yra kvadratinė šaknis iš šito vidurkio, taigi po +- 1.5 ar 2 žodžius kiekvienai raidei. O uždėjus +- dviejų procentų paklaidas ant kiekvieno raudono stulpelio tavo lentelėje matome, kad statistinę reikšmę turi tik raidės b,c,d,f,h,q,s,t ir u. Ar iš jų galima daryti kažkokias gilesnes išvadas -- nežinau, bet atrodo, kad neskaitant s ir t, atitikimas tarp raudonų ir mėlynų duomenų visai neblogas.
100 yra visgi pakankamas kiekis, kad pagal vieną faktorių pasiskirstymą tikrinti jau galėtume, kad ir grubiai.
Pagal pasiskirstymus -- galėtume imti didžiausius inputus, tada išsispręstų tamstos keliamas klausimas dėl statistinio reikšmingumo, t.y., nuokrypių apibrėžiamo kvadrato ribose (kitaip tariant, triukšmą nufiltruojam). T.y., viskas pasimato, tiesiog surūšiavus pagal inputo dažnumus.
Padariau dar vieną grafikėlį, pagal kurį matosi, kad atitikimo nėra, kaip bežiūrėtume -- http://rokiskis.popo.lt/files/2010/12/zodziu_pasiskirstymas_vlkk_rusiuotas_pagal_anglu.jpg
Beje, būtent dėl to, kad nėra atitikimo, man tas dokumentas ir užkliuvo. Kadangi tame doke pagal pirmas abėcėlės raides buvo daugiau žodžių, nei pagal paskutines, tai ir pasirodė nenormalu. Vat ir padariau paskaičiavimus.
Prieš darydamas, galvojau, kad šiaip pradžioj abėcėlės jie dirba su entuziazmu, o paskui, kai entuziazmas dingsta -- atmestinai, bet paaiškėjo, kad yra aiškios fragmentinės skylės pagal raides, t.y., užduočių vydymo nekontroliavimo požymiai.
O gal galėtum padaryti dar vieną grafiką, kur surūšiuota pagal output’o dažnumą? 🙂
Padariau, va -- http://rokiskis.popo.lt/files/2010/12/zodziu_pasiskirstymas_vlkk_rusiuotas_pagal_lietuviu.jpg
Dėkui. Man vis tiek atrodo, kad paėmus statistiškai reikšmingus duomenis, atitikimas yra visai pakenčiamas, išskyrus keletą ryškių skirtumų (t ir q). Bet tu gal apie VLKK veiklą daugiau žinai už mane, tai nesiginčysiu daugiau.
Atitinka pas maždaug pusę iš tų statistiškai reikšmingų. Jei į šių tarpą paimam 8 didžiausias ir tariam, kad modelį atitinka b, c, f, d, tai tokiu atveju turim šių modelį neatitinkančias t, h, q, s. Dėl apvalesnio skaičiaus galim pridėti dar u ir k, bet jei pas u atitinka, tai pas k vėl greičiau neatitinka.
Panašus rezultatas gaunasi ir pagal inputo atitikimus.
Trumpai tariant, atitikimai yra pakankami, kad inputą kažkaip susiet su outputu (t.y., rodo, kad modelis anglų-lietuvių veikia), bet nepakankamas, kad modelį laikyti tolygiai veikiančiu (t.y., gabalai iš outputo atrodo iškarpyti).
T.y., tą ir demonstruojam: anglų kalba lemianti pagal svetimžodžius, bet VLKK darbas yra netolygus. Tiesa? 🙂
BTW, palygink su spektraline analize. Neprimena? Prie vienos raidės padarė emisiją, kai nuotaika buvo, o prie kitos -- absorbciją, kai nuotaikos nebuvo 🙂
Nu jo, sąsaja su spektrine analize tai linksma 🙂 VLKK veikia kaip kosminių dulkių ūkas tarp anglų kalbos kvazaro ir lietuviškos žemelės -- kai ką absorbuoja, kai ką pakartotinai išspinduliuoja… Liuks 🙂
Va, nuostabu, atrodo būsim atradę bendrą kalbą.
Dabar žiūrėk, kaip iš vadybinės pusės: bet kuri organizacija gamina produktą. Inputas, kaip spinduliavimas -- tai žaliavos (įskaitant ir tokias egzotiškas, kaip žodžiai). Outputas, kaip spinduliavimas -- tai produktas.
Pagal tai, kaip varijuoja produkto kokybė (linijas, esančias spektre) žaliavų kokybės variacijos atžvilgiu, galime nustatyti organizacijos vidines savybes.
Yra tokia vadybos metodologija -- Six Sigma, būtent ten pagal įvairias variacijas yra atsekinėjama, kur yra kokios bėdos, kurias reikia taisyti. Štai čia tą ir pritaikom.
Jo, daugmaž susikalbėjom. Šaunu 🙂
Visa šita diskusija preziumuoja tai, kad šis VLKK darbas turi kažkokią didelę vertę, tarsi jeigu kas nors vietoj VLKK siūlomo „šaltasis džiazas“ parašys „ramusis džiazas“, atsitiks kokia tai kam nors žala. Realiai VLKK veikla šioje srityje žalinga, nes dažnai sukuria lietuvio ausiai svetimą skambesį turinčius žodžius -- „karpačas“, o juk jų kritikuojamas „karpačis“ skamba natūraliau.
VLKK darbą tikrai galima tikrinti statistinės analizės būdu, bet šiuo atveju VLKK turi potencialų pasiteisinimą. Gal kaip tik Smetonienė vasarą aplenkusi Rokiškį patyrinėjo ir nustatė, kad pagal dažnumus labiausiai trūksta „b“ ir „c“ svetimžodžių, ir dabar mes tiesiog matome, kaip šitie šaunuoliai tvarko anksčiau užleistus darbo barus.
Matai, vertė gali būti ir teigiama, ir neigiama. Tarkim, tavo teiginys, kad VLKK veikla yra žalinga, preziumuoja juntamą neigiamą vertę. Taigi, tyrinėti verta 🙂
O dėl Smetonienės daromų statistikų -- taip, tai scenarijus, kuris galėtų pateisinti tokį netolygų pasiskirstymą. Galima būtų tai patikrinti, paėmus kokį nors 2009 metų panašios paskirties dokumentą.
Na, ponai, kaip sakoma „faktas ant veido“ :). Su skaičiais nepasiginčysi, bet kažkaip paaiškinti reikia. Yra du būdai. Pirmas -- sukritikuoti rezultato gavimo metodą ar prielaidas kaip nelogiškas ir neatitinkančias tikrovės ir todėl rezultatą reikia atmesti ar ignoruoti. Kai kas komentaruose tą ir bandė padaryti, bet (manau) nesėkmingai. Antras būdas – po šiais skaičiais (grafikais, koreliacijom, deviacijos ir t.t.) įžvelgti realius vykstančius procesus. Čia Rokiškis daro išvadą kad: „su kai kuriomis raidėmis dirbo nuoširdžiai, o kai kurias praleido išvis…“, preziumuodamas, kad VLKK dirba pagal kažkokią sistemą, tik planuoja ir kontroliuoja darbus nesėkmingai. Mano supratimu, situacija gali būti dar prastesnė: VLKK aplamai jokios sistemos, darbų planavimo ar kokybės kontrolės nėra, todėl ir svetimžodžių „imtis“ yra absoliučiai atsitiktinė ir sunkiai paaiškinama. Kaip ten bebūtų, bet ši įstaiga šioje srityje turi problemų.
Ghrmz. Man visgi matosi kažkokie sistemiškumo bandymai. Taip, aš esu labai nusistatęs prieš VLKK, bet norėčiau teigti, kad visgi tam tikrą planavimą jie bando daryti.
Labai tikėtina, kad ten buvo bandoma įdiegti kokias nors šiuolaikines valdymo sistemas.
Bet man gražiausia šioje istorijije yra tai, kad vienas sveiko mąstymo blogeris per pusdienį atlieka tokį VLKK tyrimą, kurio Valsybės kontrolė su Audito komitetu per pusmetį nevaliotų 🙂
Nežinau apie sistemas, bet taip ar anaip, paprastai rūšiuoja žmonės vienaip ar kitaip.
O dėl tyrimo -- Valstybės kontrolė ir Audito komitetas gali, kai prireikia. Tik jie turi labai mažus pajėgumus, o ant jų rezultatų neretai bbd tiriamiesiems.
Šiaip, šitas grafikėlis nėra kažkoks ypatingas, tai tiesiog paprastas problemų paieškos metodas, naudojant statistinius įrankius -- tiesiog žiūrima atitiktis modeliui.
Pagal VLKK atrandamų svetimžodžių pasiskirstymo dažnį mes negalime vertinti jų veiklos kokybės -- tai nėra rezultato rodiklis, kokiu galėtų būti pvz., atrastų svetimžodžių pakaitalų įsigalėjimo šnekamojoje kalboje lygis 1 metų laikotarpiui.
Tačiau problemų paieškai tokie dalykai, kaip tas grafikas pasiskirstymams pagal raides tinka, nes pagal juos galima atrasti bardakų požymius.
Rokiški, o kodėl tu nusprendei, kad dažniausiai vartojami žodžiai anglų kalboje labiausiai lenda į lietuvių kalbą?
Juk populiariausi žodžiai anglų kalboje tikriausiai bus visokie „the“, „this“, „that“, „I“, „and“ ir į juos panašūs -- ir jie į lietuvių kalbą nelenda. Į lietuvių kalbą pereina visokie techniniai specializuoti žodžiai.
Žodžiu -- nematau koreliacijos tarp žodžių populiarumo anglų kalboje ir jų atsiradimo lietuvių kalboje (svetimžodžių statusu).
PS: tai nereiškia, kad VLKK dirba tobulai. Mano nuomone, šitas jų darbas (žodžių sąrašų tvirtinimas nutarimais) išvis beprasmis -- bet tai jau atskira tema.
Ne dažniausiai vartojami žodžiai, o pasiskirstymo pobūdis. Nėra pagrindo galvoti, kad yra koks nors mechanizmas, kardinaliai iškreipiantis pasiskirstymų pobūdį žodžių migracijos metu -- jei migruoja atsitiktiniai žodžiai arba pan., pasiskirstymas turi išlikti.
Atitinkamai, bandant nuneigti pasiskirstymų buvimą, reikia pagrįsti pasiskirstymo dingimą kažkokiu su raidėmis susijusiu procesu, kuris tą pasiskirstymą laužo.
Rokiški, šį kartą tikrai fail. Nepyk už kritiką ir nuomonę, bet kai ne vienas žmogus suabejoja tavo teorija (ji yra tik tavo ir nepatvirtinta jokiais rimtesniais įrodymais), tai reikėtų parodyt tam tikrą toleranciją ir kitokiai nuomonei, kuri paremta lygiai tos pačios vertės įrodymais kaip ir tavo. Kitu atveju viskas bus panašiai kaip su violetine minia.
Aš esu visada prieš skubotus ir labai kategoriškus sprendimus, ypač tokius, kurie ką nors „nuteisia“.
P.S. pastebėjau tendenciją, kad visi nuolatinesni blogeriai, karts nuo karto iškeliantys savo „sąmokslo teorijas“, baisiai įpyksta ir, net iki paraudonavimo įrodinėdami savo, į konstruktyvias kritikas pradeda šaudyt „debilų“, „dudndukų“ ir pan. bombom. Pasaulis nėra vien juodas ir baltas. Pasaulyj nėr vienos tiesos.
Tikinčių ar netikinčių žmonių skaičius nerodo nieko, ypač, kai tie žmonės neturi elementaraus supratimo apie statistiką. Pasaulyje yra šimtai milijonų tikinčių, kad pasaulis plokščias, tačiau nuo to pasaulis nepasidaro plokščias.
Vienintelis prieštaravimas, vertas dėmesio, buvo išsakytas Laiqualasse -- kad imtis visgi per maža patikimoms išvadoms, esant dalinimui į 26 segmentus, nes vienam vidutiniškai tenka ~4 žodžiai, todėl foninės variacijos įtaka per didelė mažesniems segmentams.
O tamstos dvasinguminės pastabos apie „pasaulyj nėr vienos tiesos“ ir pan. neneša argumento, kuris ką nors teigtų ar neigtų.
Kažkaip užklydau į šitą temą ir dar pagalvojau apie vieną dalyką -- gal pamatysi ir pakomentuosi. Paimkim, pavyzdžiui, populiariausių angliškų žodžių sąrašą (http://www.world-english.org/english500.htm) ir pažiūrėkim į pirmą dešimtuką. Matome pirmas raides T, O, I, A, Y. Jei pridedame ir antrą, atsiranda H ir W; trečią -- B. Šitų žodžių dažnumas labai iškreipia duomenis, nes nei vienas iš jų nėra toks, kuris galėtų ateiti į lietuvių kalbą, kaip svetimžodis. Ir tavo grafikuose matyti, kad anglų kalbos žodžių pirmų raidžių dažnis labai didelis prie būtent šių raidžių. Labai įdomu būtų pažiūrėti, kaip tie duomenys pasikeistų, atmetus pirmus X populiariausių žodžių, kur X yra 10, 50 ar 100.
…aišku, tik parašęs komentarą pamačiau, kad šiek tiek aukščiau c2h5oh kažką panašaus jau rašė. Iš esmės pritariu tam pastebėjimui -- būtent labai dažnai anglų kalboje pasitaikantys žodžiai smarkiai paveikia kai kurių raidžių statistinius svorius; iš kitos pusės, žodžio dažnumas kalboje turi nedaug įtakos to žodžio tapimui svetimžodiu (gal net priešingai -- dažnai naudojami tokie kasdieniai žodžiai, kurie paprastai kitose kalbose jau turi atitikmenis, taigi jiems migruoti nėra reikalo; o naujadarai ir specifiniai terminai, kurie šiaip vartojami retai, migruoja lengvai).