Pasitaikė man toks dokumentas – „Valstybinės lietuvių kalbos komisijos protokolinis nutarimas dėl svetimžodžių atitikmenų sąrašo“, pasirašytas VLKK vadovės Irenos Smetonienės 2010 spalio 28 dieną.
Nesigilinsiu šį kartą į tai, ką ten prigalvoję yra kaitalioti (kaip visada, priežasčių pasijuokimams galima atrasti), tačiau pabandžiau tiesiog formaliai skaitiškai įvertinti tos komisijos darbo kokybę – kiek jie makliavoja, o kiek nuoširdžiai stengiasi. Kriterijus – labai paprastas: siūlomų keisti svetimžodžių pasiskirstymo atitikimas prognozuojamam statistiniam svetimžodžių paplitimui.
Prielaidos paprastos: pagrindinis svetimžodžių šaltinis šiuo metu yra anglų kalba. Taigi, galime tikėtis, kad lietuvių kalbos gaunamų svetimžodžių pasiskirstymas turėtų ganėtinai stipriai koreliuoti su pačios anglų kalbos žodžių pasiskirstymu. Pavyzdžiui, paprasčiausiu atveju – pagal pirmąją žodžio raidę.
Tuo atveju, jei VLKK dirbtų kokybiškai, sistemingai ir organizuotai ieškodama plintančių svetimžodžių bei pakaitalų jiems, dažniniai nuokrypiai nuo anglų kalbos pasiskirstymo turėtų būti ganėtinai saikingi, didele dalimi grafikai turėtų sutapti. Priešingu, prasto darbo atveju, turėtume gauti visiškai neatitinkančius pasiskirstymus.
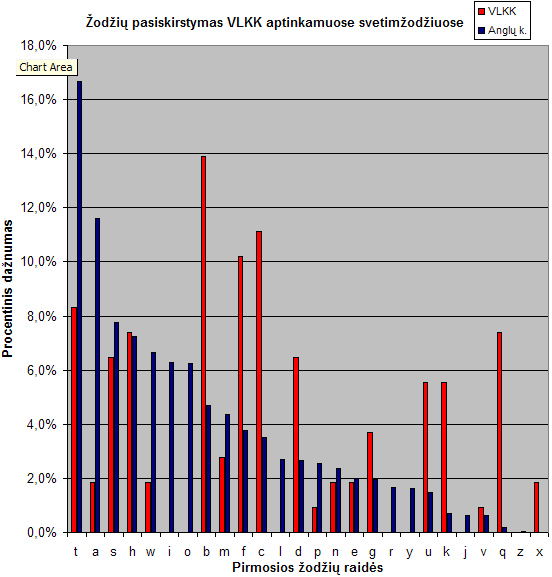
Taigi, sumetam lentelę iš to dokumento, paskaičiuojam, sumetam greta angliškus pasiskirstymus ir gauname štai ką:
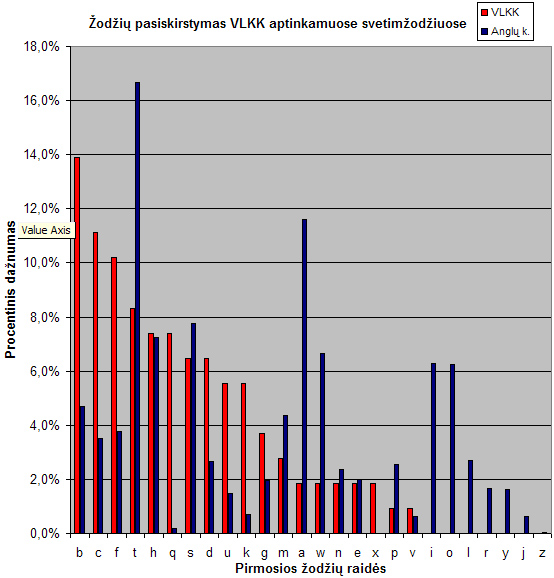
Grafikas vaizduoja lietuvių kalboje keičiamų svetimžodžių pasiskirstymą pagal VLKK (raudona) ir anglų kalbos žodžių pasiskirstymą (mėlyna)
Kaip matome, bendros koreliacijos nematome. Visiškai. Dar daugiau, įspūdis toksai, kad pradedant abėcėlės pirmomis raidėmis, VLKK dar bando dirbti aktyviai, tačiau įpusėjus abėcėlę, nuleidžia rankas ir daugiau jau nesistengia. Negana to, labai keistai atrodo kelių raidžių trūkumai – toks vaizdas, kad ieškant svetimžodžių, dirbta buvo visgi pagal konkrečias raides (t.y., ar tai kažkokiems darbuotojams paskirta rankioti svetimžodžius, ar šiaip, bet paraidžiui), tačiau dėl kažkokių neaiškių priežasčių kelios svarbios raidės tiesiog prapuolė. Fenomenaliai atrodo „a“ raidė – nors ir pirma, sąrašo pradžioje, tačiau visiškai menkai teparankiota.
Toliau esantys skirtumai tarp angliškų ir lietuviškų „b“, „c“, „d“ (praleidžiam iškrentančią „e“) ir paskui dar ir „f“ bei daugmaž „g“ – savo santykiais koreliuoja tarpusavy, t.y., atrodo, kad su šiomis raidėmis buvo dirbta kokybiškai, nuosekliai, jų santykiai atitinka ir mūsų darytą prielaidą apie atitikimą tarp svetimžodžių ir angliškų žodžių pasiskirstymo, patvirtindami, kad šito mūsų tyrimo konceptas teisingas.
Su „h“ raide jau prasideda kažkokie bardakai – bene vienintelė procentiškai atitinkanti raidė tampa išimtimi iš bendro grafiko. Su „i“ raide – išvis nei vieno svetimžodžio nerasta. Su „o“ – irgi. O juk šiomis raidėmis prasidedantys žodžiai užima 5-ą ir 6-ą vietą pagal populiarumą anglų kalboje. Dar kartą prisiminkim „a“ raidės fenomeną. Su juo palyginus, „w“ bei „l“ jau atrodo nekaltai.
Galų gale, dar toliau – išvis nelieka jokių abejonių: „t“ raide prasidedančių svetimžodžių VLKK atranda mažiau, nei atrado prasidedančių „b“, „c“ ar „f“ raidėmis. O juk „t“ raide prasidedantys anglų kalbos žodžiai – populiariausi. Kiek čia mums gaunasi? Maždaug keturių kartų skirtumas. Keturių kartų neatitikimas yra labai didelis, sakyčiau, užribinis, abejoti neleidžiantis. Kad tai nėra kažkokia fluktuacija, abejot neleidžia „m“, „s“ ir „w“ santykiai, kurie irgi panašūs.
Taigi, VLKK darbas, sprendžiant pagal statistinės atitikties realybei vertinimą, yra prastas, o pagal gautus duomenis (t.y., raidžių pasiskirstymų pobūdį) galime spėti, kad ten yra labai nemenkų organizacinių bėdų, susijusių su konkrečių užduočių vykdymu. VLKK dirba nesistemingai, prastai planuoja savo veiklą ir prastai kontroliuoja savo pačios darbą.
Ar ką nors bent truputį nustebinau?
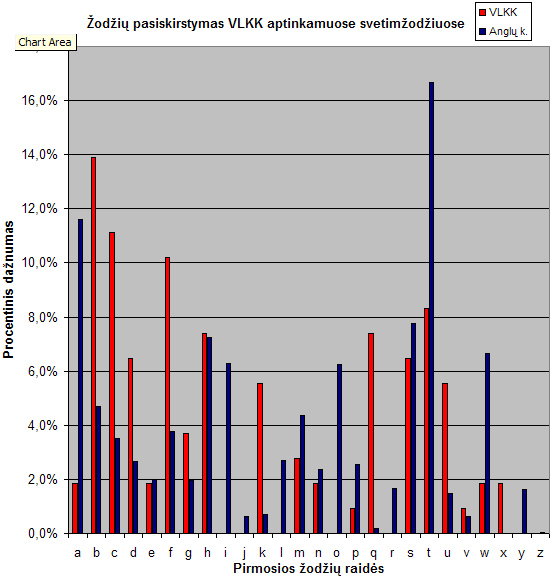
Upd.: dar rūšiuotas grafikas pridėtas, kad kitu būdu pažiūrėt, aiškiau matosi pasiskirstymų neatitikimas.
-
- Grafikas vaizduoja svetimžodžių pasiskirstymą pagal VLKK (raudona) ir anglų kalbos žodžių pasiskirstymą (mėlyna)
-
- Tas pats grafikas, surūšiuotas pagal pasiskirstymų dažnumą anglų kalboje. Matosi, kad VLKK pikai visiškai neatitinka.
-
- Tas pats grafikas, surūšiuotas pagal pasiskirstymų dažnumą lietuvių kalboje. Matosi, kad anglų kalbos pikai visiškai neatitinka.